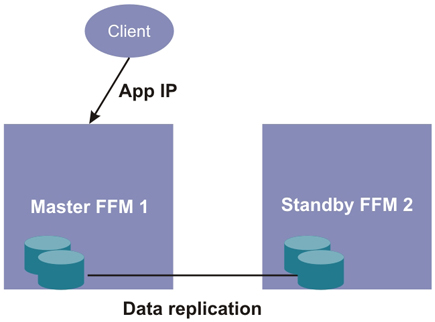
The Fabric Manager high availability cluster uses the Distributed Replication Block Device (DRBD) to replicate several types of data between the cluster nodes. This capability is a software-based, shared-nothing replicated storage solution mirroring the content of block devices (disk partitions) between hosts. That is, the DRBD copies data from the primary node to the secondary node ensuring that both copies of the data remain identical. It replicates data in real time without the applications being aware that the data is stored on multiple hosts in a synchronous manner.
The following simple diagram illustrates that each node contains local disks that are replicated between the two cluster nodes.
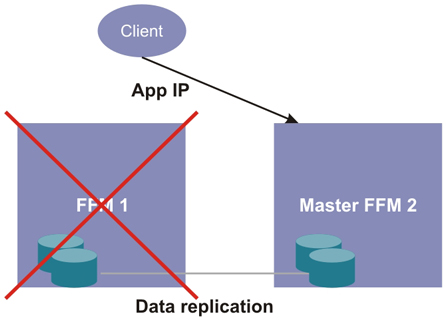
In the case where the master Fabric Manager node fails, the second (standby) node automatically becomes the master node. The application access point automatically moves to the second node so that clients can continue to have access, as shown in the following figure.
Understanding the Distributed Replication Block Device
The core functionality of the DRBD is implemented through the Linux kernel module. Because the DRBD is situated near the bottom of the I/O stack for a system and constitutes a driver for a virtual block device (disk), it provides a flexible and versatile replication solution that adds high availability to just about any application.
By definition and the Linux kernel architecture, the DRBD is separate and independent of the layers above it. It cannot add features to upper layers that they do not possess.
The DRBD uses a managed virtual block device, /dev/drbr0, in the Fabric Manager high availability cluster where the postgres data is mapped. The /dev/sda3 disk partition in the Fabric Manager high availability cluster is associated with the DRBD block device.
A file system is created on top of where the directories to be shared are stored. The Fabric Manager high availability cluster shares several directories, replicating the contents of the directories with DRBD. The replicated contents include postgres data, dumps, nagios/etc, nagios/var, and some Tomcat data. The Fabric Manager high availability mount point is /mnt/ffmha.
The DRBD resource is either primary or secondary. When it is primary, the postgres database and other Fabric Manager resources run on this cluster node. When it is secondary, it receives all updates from the peer node’s device but otherwise disallows access completely.
The Fabric Manager high availability cluster uses DRBD synchronous replication mode. That is, local write operations on the primary node are considered completed only after both the local and remote disk write have been confirmed. Thus, a single node loss does not lead to any data loss. However, if both nodes are destroyed at the same time, data loss occurs.
Data replication occurs in the Fabric Manager cluster over the ClearPath Forward Management LAN (FM LAN) static IP address.
The DRBD provides automatic recovery from split-brain situations, which might occur if the card to the ClearPath Forward Management LAN (FM LAN) fails. Once connectivity becomes available again and peer nodes exchange the initial DRBD protocol handshake, DRBD detects the split-brain situation. If it detects that both nodes are in the primary role, it immediately tears down the replication connection and tries to recover, resyncing the data.
Note: The Distributed Replication Block Device used with the Fabric Manager cluster is configured with Fabric Manager cluster definitions by default. You can find background information and other information about the DRBD in the DRBD User Guide from LinBit at http://www.drbd.org.