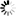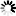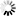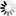In a normal sort operation, records are continually handled throughout the stringing and merging phases. In other words, the sort algorithms are concerned only with the various keys, but the entire record—including the keys---is carried along throughout the sorting process.
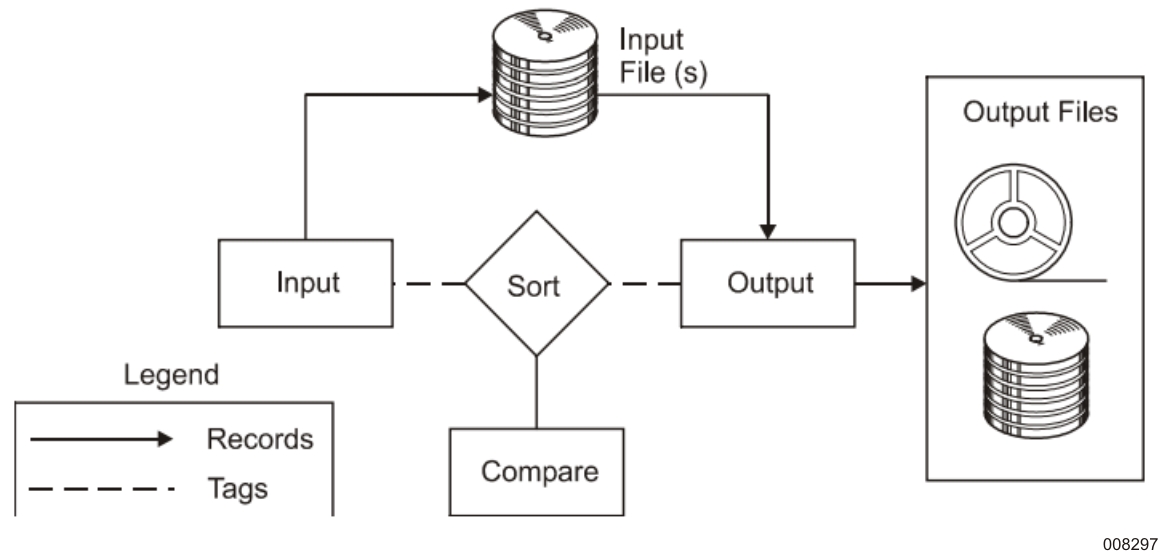
For files that have large records and small keys, it might be more efficient to perform a tag sort. In tag sorting, only the keys and the address of each record are handled throughout the sorting process.
In performing a tag sort, you must provide an input procedure that filters the incoming records, extracting the sort keys and appending the disk address of the location of the entire record. The keys are arranged by the input procedure in a contiguous string. This tag is then submitted to the stringing phase. This structure eliminates the need to accumulate the keys from various fields in the record whenever a comparison is required.
During the final merging phase, the output procedure uses the address portion of the tag to retrieve the records in the correct sequence.
The input file is read twice: once by the input procedure (in a serial fashion) for the stringing phase, and once again by the output procedure (in a random fashion) for the final merge phase. Tag sorting requires less disk and memory space to complete the job. Retrieving the output records is the most time-consuming factor and is highly data-dependent.
If a sort program is heavily used, both entire-record and tag sorts should be tested to determine which sort operation produces the best results.
Creating a Tag shows the extraction of one or more keys from the incoming record and the building of the tag.
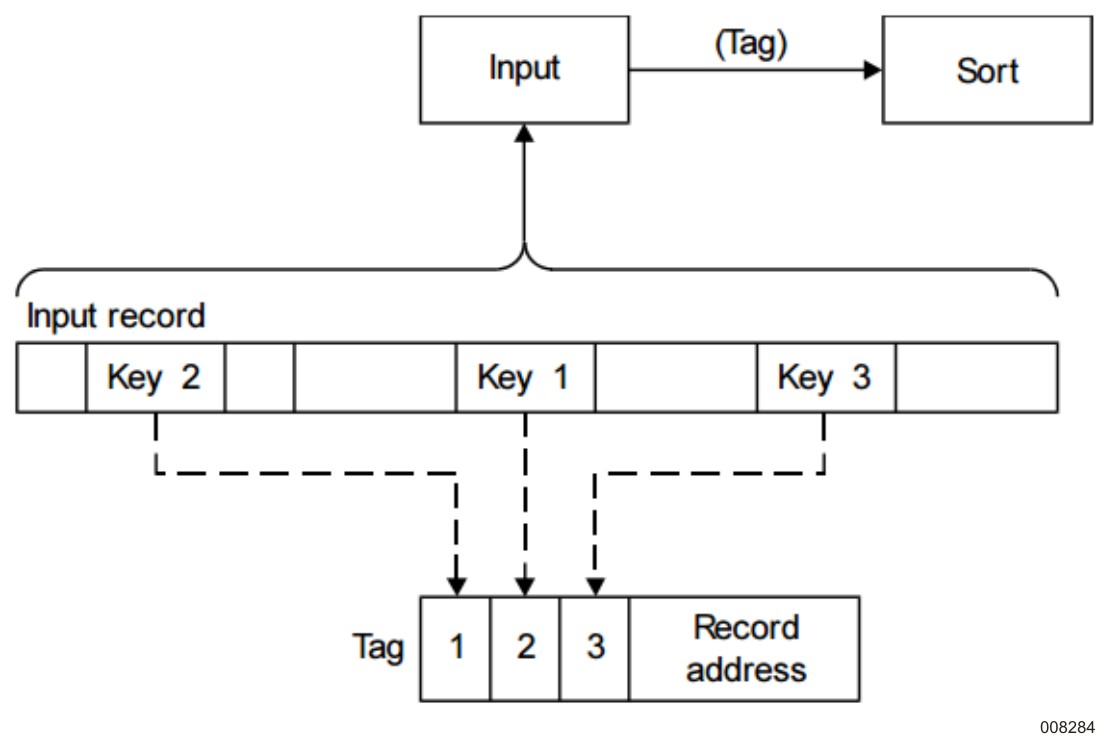
Tag Sort, Nondisk Input File shows a functional diagram of a tag sort that has one or more nondisk input files. The input file must be copied in its entirety to disk.
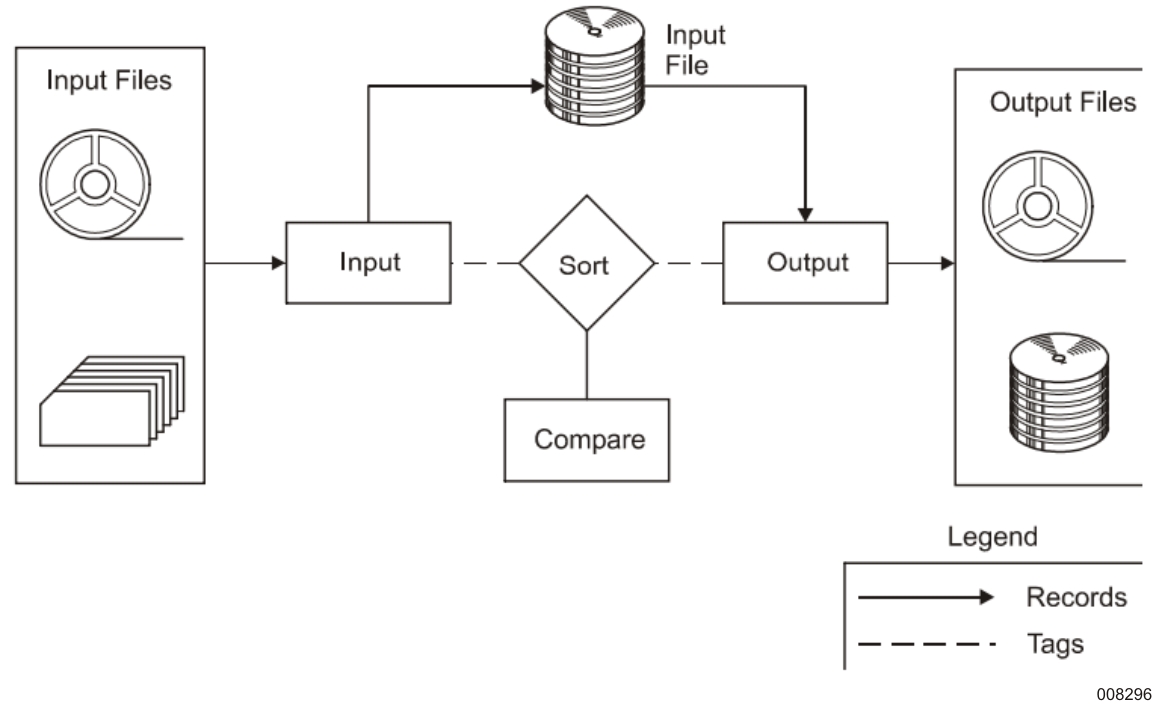
Tag Sort, Disk Input File shows the functional diagram of a tag sort that has a disk file as its input medium.