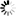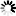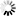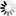A simple value is a single scalar value either defined by the user or derived from a value in a memory location or in a stack. A simple value is a word value followed by an optional concatenation value. The <simple value> construct is often used in the PV command.
Syntax
<simple value>
──<word value>─┬──────────────────────────┬────────────────────────────┤
│ ┌◄─────────────────────┐ │
└─┴─ & ──<concatenation>─┴─┘<word value>
──<simple word>─┬─────────────────────┬────────────────────────────────┤
└─ . ──<partial word>─┘<simple word>
──┬─ M ── [ ──<hexadecimal address>── ] ───────────────┬───────────────┤ ├─ C ── ( ─┬─<simple location>──┬─ ) ────────────────┤ │ └─<absolute address>─┘ │ ├─<number>───────────────────────────────────────────┤ ├─<simple location>──┬─ [ ──<simple index list>── ] ─┤ ├─<absolute address>─┘ │ ├─ ( ──<simple value>── ) ───────────────────────────┤ └─<formatted hexadecimal word>───────────────────────┘
<simple index list>
┌◄────── , ──────┐ ──┴─<simple value>─┴───────────────────────────────────────────────────┤
<partial word>
──┬─ [ ──<simple value>── : ──<simple value>── ] ─┬────────────────────┤ └─ TAG ─────────────────────────────────────────┘
<concatenation>
──<word value>─────────────────────────────────────────────────────────► ►─┬─ [ ──<left bit to>── : ──<left bit from>── : ──<bit count>── ] ─┬──┤ ├─ [ ──<left bit to>── : ──<bit count>── ] ───────────────────────┤ └─ TAG ───────────────────────────────────────────────────────────┘
<left bit to>
──<simple value>───────────────────────────────────────────────────────┤
<left bit from>
──<simple value>───────────────────────────────────────────────────────┤
<bit count>
──<simple value>───────────────────────────────────────────────────────┤
Explanation
The following text describes the meaning of each variable:
<word value>
Specifies a simple word with an optional partial word. The following groups of options represent valid simple words.
M [<simple address>]
Obtains the contents of the memory location at the hexadecimal address. This operation is the same as subscripting the MEMORY array.
C (<simple location>)
C (<absolute address>)
Obtain the contents of any simple location or absolute address.
<number>
This construct is defined earlier in this section.
DUMPANALYZER assumes a number is in hexadecimal form unless you precede it with either DEC, for decimal form, or OCT, for octal form. For example, you could use either of the following constructs to indicate bit 47 for 6 in a partial word:
[2E:6] [DEC 47:6]
<simple location> [ <simple index list> ]
<absolute address> [ <simple index list> ]
Specify an index to a simple location or absolute address. The derived value can be used as a simple word. This method of forming values is valid only if the word specified (which can be reached through an IRW chain) is an unindexed data descriptor, and the number of indexes specified matches the number of dimensions in the array.
<partial word>
Specifies a particular group of bits within the simple word. A partial word is an optional component of a word value. When a partial word is present, the word value is the value of a selected group of bits within the simple word.
<simple value>:<simple value>
Specifies a partial word with two simple values separated by a colon (:). The first simple value indicates the number of the starting bit in a range. The second simple value indicates the number of bits over which the range extends. The range can extend from 47 to 0. The direction proceeds from the specified first simple value down to the value specified by the second simple value.
TAG
Specifies the value of the 4–bit TAG in the attached simple word.
<word value> & <concatenation>
Indicates a substitution of certain bits to be made from the second word value into the first. In the context of concatenation, a word value is a 48–bit, binary word. The concatenation variable includes within itself a second word value, along with bit specifiers and a bit count; For further information about bit manipulation, see the ALGOL Programming Reference Manual, Volume 1: Basic Implementation.
<word value> & <word value> [<left bit to>:<left bit from>:<bit count>]
Specifies a destination word followed by a source word. The first word value represents a binary, 48–bit word with a 4–bit tag value. The <left bit to> variable defines the highest (ranging from 47 down to 0) bit number in the destination word. The <left bit from> variable defines the highest (ranging from 47 down to 0) bit location in the source word. The bit count, ranging from 1 through 48, specifies the length of the data field to be moved from the source word to the destination word.
<word value> [<left bit to>:<bit count>]
Represents a binary, 48–bit word with a 4–bit tag value. The <left bit to> variable defines the highest (ranging from 47 down to 0) bit number in the destination word. In this case, the <left bit from> specification coincides with the <left bit to> specification. The bit count specifies the length of the data field to be moved from the source word to the destination word.
<word value> TAG
Represents a binary, 48–bit word with the preceding tag value. TAG indicates that the TAG of the source word is to be substituted for the TAG in the destination word.
<formatted hexadecimal word>
──<tag value>──<blank>──<high-order six hexades>──────────────────────►
►─<blank>──<low-order six hexades>─────────────────────────────────────┤
DUMPANALYZER often presents the contents of a word in the form:
t hhhhhh hhhhhh
DUMPANALYZER will recognize and properly interpret this type of word structure in lieu of a word whose structure is of the form:
hhhhhhhhhhhh & t TAG
This provides the user the ability to cut and paste words presented by DUMPANALYZER to be used as input to other, subsequent DUMPANALYZER commands.
A word of the form:
D 123456 789ABC
is interpreted exactly as a word in the form:
123456789ABC & D TAG
The parsing rules for words of the form:
t hhhhhh hhhhhh
require that ONLY one blank character is to be used to separate the <tag value> from the <high-order six hexades> and that ONLY one blank character is to be used to separate the <high-order six hexades> from the <low-order six hexades>. Any command text immediately following the <low-order six hexades> cannot be a hexadecimal digit.
<tag value>
A single hexadecimal digit.
<high-order six hexades>
<low-order six hexades>
Six adjacent hexadecimal digits with no imbedded blank characters.
<EPSILON formatted hex word>
───┬─────────────────────┬────<tag value>──<blank>──<high-order six hexades>────► └─<extension value>───┘
►─<blank>──<low-order six hexades>─────────────────────────────────────┤
When analyzing a dump created by an E-mode level Epsilon MCP, DUMPANALYZER often presents the contents of words in the form:
t hhhhhh hhhhhh
or
e t hhhhhh hhhhhh
DUMPANALYZER will recognize and properly interpret this type of word structure in lieu of a word that has the structure:
hhhhhhhhhhhh & t TAG
or
hhhhhhhhhhhh & t TAG & e EXT
This provides the user the ability to cut and paste words presented by DUMPANALYZER as input to other commands.
A word of the form:
D 123456 789ABC
is interpreted exactly as a word of the form:
123456789ABC & D TAG
<extension value>
An optional single hexadecimal digit that contains the extension field defined in E-mode level Epsilon. This field normally contains the high-order bits in the ASD number of a control word. Because the field is zero for the first 8M ASD numbers and is not used in operands, a blank is inserted in place of a zero value so that word formatting looks similar to all previous versions of DUMPANALYZER.
<tag value>
A single hexadecimal digit containing the tag field of an E-mode word dumped from memory.
<high-order six hexades>
<low-order six hexades>
Six adjacent hexadecimal digits containing bits [47:24] and bits [23:24] respectively, of an E-mode word.
<ETA formatted hex word>
──<tag value>──<blank>──<high-order nine hexades>──────────────────────►
►─<blank>──<low-order six hexades>─────────────────────────────────────┤
When analyzing a dump created by an E-mode level ETA MCP, DUMPANALYZER often presents the contents of words in the form:
t eeehhhhhh hhhhhh
where the “hhhhhh hhhhhh” represent the 48-bit word format used in all previous MCP dumps. The “eee” part of the <high-order nine hexades> contains the word extension containing the high-order bits of an ASD number contained in the 64-bit word. As in all previous MCP dumps, the “t” displays the tag of the word.
DUMPANALYZER will recognize and properly interpret this type of word structure in lieu of a word that has the structure:
hhhhhhhhhhhh & t TAG & eee EXT
This provides the user the ability to cut and paste words presented by DUMPANALYZER as input to other commands.
A word of the form:
D 123456789 ABCDEF
is interpreted exactly as a word of the form:
456789ABCDEF & D TAG & 123 EXT
<tag value>
A single hexadecimal digit containing the tag field of an E-mode word dumped from memory.
<high-order nine hexades>
Nine adjacent hexadecimal digits. The left three hexadecimal digits contain the high-order ASD bits in a control word. The adjacent six hexadecimal digits (the “h” in “eeehhhhhh”) contain bits [47:24] of a 48-bit E-mode word.
<low-order six hexades>
Six adjacent hexadecimal digits containing bits [23:24] of the 48-bit operand. For example, bits [47:48] in an E-mode word.
Examples
In the following examples, spaces and special characters function as delimiters. You need to use delimiters whenever two alphanumeric items are juxtaposed.
|
Simple Value |
Description |
|
M[47AC] |
%MEMORY LOCATION |
|
C (G HLUNIT) |
%CONTENTS OF SIMPLE LOCATION |
|
DEC 123456 & 3 TAG |
%CONCATENATION |
|
C (STK 53 BOSR).[6:2] |
%PARTIAL WORD |